Work
The items on this page are fairly brief presentations of different
products of research work. So as well as short text pieces they
include charts, maps, software and so on. They’re here in part simply
to illustrate some of my work to a general audience. There’s also a
particular focus on the production and circulation of data, charts, maps
and so on - so on the making and uses of research.
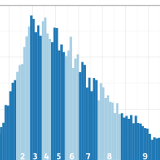
This is an introduction to using the sample survey Households Below
Average Income in the
R Statistics Package. With this you have
all you need to carry out analysis of the distribution of income in the
UK using the world’s finest open-source software.
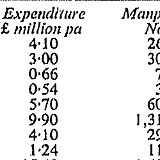
This is lightly adapted from a
blog post
for the LSE policy and politics blog, which also appeared on the RSS’s
website
Stats Life
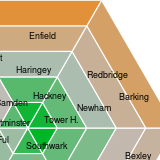
In the course of research on trends in poverty in London from 2000 to
2011, some interesting findings on the spatial distribution of poverty
in the city emerged. These suggested that, at neighbourhood level,
poverty rates in much of the historically deprived inner city
had fallen, sometimes quite dramatically. Over the same period poverty
rates had increased in suburban areas.
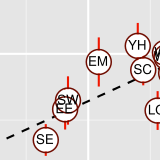
Data on welfare benefits are widely used in research and public
administration to describe spatial variations in the prevalence of
poverty in the UK. Many poor households, however, receive no benefits,
and not all benefit recipients are income-poor. Are statistics on
benefits receipts, then, really good proxies for describing the
geography of poverty?
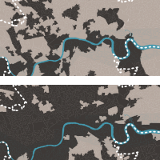
The maps show the parts of London where housing is affordable and
accessible for low-income private tenants who get Housing Benefit to
help pay their rent. Changes to Housing Benefit introduced in 2010 were
very likely to reduce the amount of housing affordable to low-income
tenants, especially in inner London.
Since around 2001 I’ve been using the
Ruby programming language for everyday
programming needs. Amongst other things, I used the
WxRuby package to write desktop
applications using Ruby, most notably the Weft QDA software for
analysing qualitative data analysis. For several years from around 2006
I also led development of WxRuby.
Weft QDA is/was a free, open-source package for the analysis of
qualitative (unstructured text) data. I originally wrote it in 2003-2004
to analyse interviews and field notes from my MSc dissertation research
on credit unions in South London.
